用 Z 表示一个随机变量,其概率密度函数为 f(z),累积分布函数为 F(z)。定义函数
L(Z,Z^)=ρ⋅max(Z−Z^,0)+(1−ρ)⋅max(Z^−Z,0)
其中 Z^∈R,ρ∈(0,1)。求使得 L(Z,Z^) 的期望最小的 Z^ 的取值。
L(Z,Z^) 的期望为
E[L(Z,Z^)]=∫−∞+∞L(z,Z^)f(z)dz=ρ∫Z^+∞(z−Z^)f(z)dz+(1−ρ)∫−∞Z^(Z^−z)f(z)dz
令
∂Z^∂E[L(Z,Z^)]=0=−ρ∫Z^+∞f(z)dz+(1−ρ)∫−∞Z^f(z)dz=−ρ[1−F(Z^)]+(1−ρ)F(Z^)=F(Z^)−ρ
解得
Z^∗=F−1(ρ)
即使得 L(Z,Z^) 的期望最小的 Z^ 的取值为 Z 的 ρ 分位数。
在 DeepAR 等模型中,我们的预测目标是某个确定形式的概率分布的参数,通过最大化对数似然来优化网络。如果我们把预测的目标改为分位数,用 L(⋅) 作为损失函数呢?下图是实验的结果:
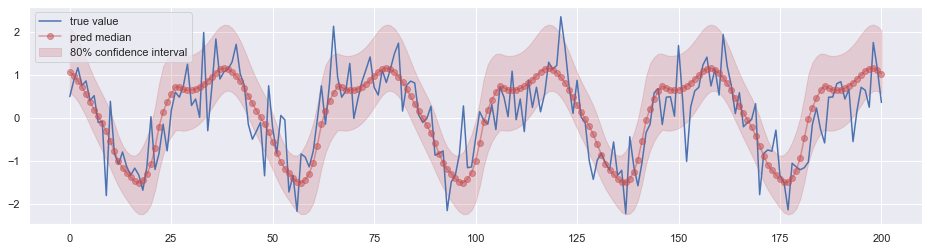
看起来也不错。且这种方式并不预先假设分布的具体形式,似乎更加通用一些。