最近学习了一种结合了深度学习和状态空间模型的时间序列预测方法(见《时间序列预测方法之 DeepState》),该方法需要用到卡尔曼滤波。
卡尔曼滤波是一种高效的自回归滤波器,它能够从一系列不完全及包含噪声的测量中,估计动态系统的状态。在导航、运动控制、时间序列分析等领域都有重要应用。
卡尔曼滤波的公式比较多,乍一看容易懵。根据我多年的经验,遇到让人头疼的公式,自己试着推导一遍,肯定会更头疼, 比较有助于理解。
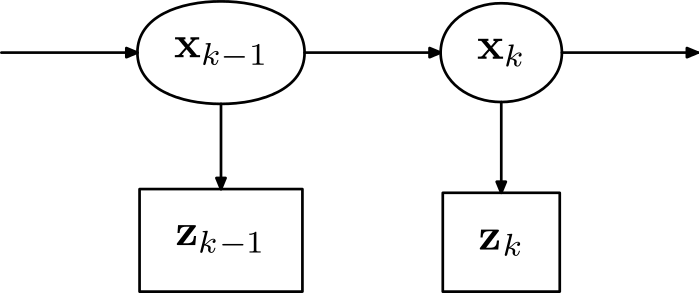
先简单介绍一下状态空间模型。如下图所示。系统的状态 {xk}构成一条马尔科夫链。我们无法直接观测状态 xk,而是通过可观测的量 zk 来估计当前的状态。
考虑一个线性高斯状态空间模型,有
xk=Fkxk−1+Bkuk+wk(1)
其中 xk 表示 k 时刻系统的状态,Fk 是状态转移模型,uk 表示 k 时刻系统的输入,Bk 是输入控制模型,wk 是状态转移时的噪声,满足 wk∼N(0,Qk)。
zk=Hkxk+vk(2)
其中 zk 是 k 时刻的观测值,Hk 是观测模型亦即从真实状态空间到观测空间的映射,vk 是观测时的噪声,满足 vk∼N(0,Rk)。
在已知 k−1 个观测值的情况下,我们可以估计 k 时刻的状态:
x^k∣k−1=Fkx^k−1∣k−1+Bkuk(3)
在得到第 k 个观测值后,计算观测值与估计的观测值之间的偏差:
y~k=zk−Hkx^k∣k−1(4)
从而可以对估计的状态作出修正:
x^k∣k=x^k∣k−1+Kky~k(5)
这很明显是一个贝叶斯主义者的做法:你先有个信念(估计),在得到新的证据(观测值)后,以一定的权重更新你的信念。
这里的权重 Kk 被称为增益。接下来我们来推导最优的增益。先考虑以下几个协方差:
Pk∣kPk∣k−1Sk=cov(xk−x^k∣k)=cov(xk−x^k∣k−1)=cov(y~k)(6)
在接下来的推导中,我会尽可能给出完整的中间步骤。
Sk=cov(y~k)=cov(zk−Hkx^k∣k−1)=cov(Hkxk+vk−Hkx^k∣k−1)=cov(Hk(xk−x^k∣k−1)+vk)=Hkcov(xk−x^k∣k−1)Hk⊤+cov(vk)=HkPk∣k−1Hk⊤+Rk(7)
Pk∣k−1=cov(xk−x^k∣k−1)=cov(Fkxk−1+Bkuk+wk−(Fkx^k−1∣k−1+Bkuk))=cov(Fk(xk−1−x^k−1∣k−1)+wk)=Fkcov(xk−1−x^k−1∣k−1)Fk⊤+cov(wk)=FkPk−1∣k−1Fk⊤+Qk(8)
而
Pk∣k=cov(xk−x^k∣k)=cov(xk−x^k∣k−1−Kky~k)=cov(xk−x^k∣k−1−Kk(zk−Hkx^k∣k−1))=cov(xk−x^k∣k−1−Kk(Hkxk+vk−Hkx^k∣k−1))=cov((I−KkHk)(xk−x^k∣k−1)−Kkvk)=(I−KkHk)cov(xk−x^k∣k−1)(I−KkHk)⊤+Kkcov(vk)Kk⊤=(I−KkHk)Pk∣k−1(I−KkHk)⊤+KkRkKk⊤=Pk∣k−1−KkHkPk∣k−1−Pk∣k−1Hk⊤Kk⊤+KkHkPk∣k−1Hk⊤Kk⊤+KkRkKk⊤=Pk∣k−1−KkHkPk∣k−1−Pk∣k−1Hk⊤Kk⊤+Kk(HkPk∣k−1HkT+Rk)Kk⊤=Pk∣k−1−KkHkPk∣k−1−Pk∣k−1Hk⊤Kk⊤+KkSkKk⊤(9)
优化的目标是最小化均方误差,即最小化 E[∣xk−x^k∣k∣2]=tr(Pk∣k)。令
∂Kk∂tr(Pk∣k)=0=∂Kk∂tr(Pk∣k−1−KkHkPk∣k−1−Pk∣k−1Hk⊤Kk⊤+KkSkKk⊤)=∂Kk∂[−tr(KkHkPk∣k−1)−tr(Pk∣k−1Hk⊤Kk⊤)+tr(KkSkKk⊤)]=∂Kk∂[−tr(KkHkPk∣k−1)−tr(Pk∣k−1(KkHk)⊤)+tr(KkSkKk⊤)]=∂Kk∂[−tr(KkHkPk∣k−1)−tr((KkHkPk∣k−1top)⊤)+tr(KkSkKk⊤)]=∂Kk∂[−tr(KkHkPk∣k−1)−tr((KkHkPk∣k−1)⊤)+tr(KkSkKk⊤)]=∂Kk∂[−tr(KkHkPk∣k−1)−tr(KkHkPk∣k−1)+tr(KkSkKk⊤)]=∂Kk∂[−2tr(KkHkPk∣k−1)+tr(KkSkKk⊤)]=−2(HkPk∣k−1)⊤+KkSk+KkSk⊤=−2(HkPk∣k−1)⊤+2KkSk(10)
解得最优卡尔曼增益
Kk=(HkPk∣k−1)⊤Sk−1=Pk∣k−1Hk⊤Sk−1(11)
此时式 (9) 可以进一步简化为
Pk∣k=Pk∣k−1−KkHkPk∣k−1−Pk∣k−1Hk⊤Kk⊤+KkSkKk⊤=Pk∣k−1−KkHkPk∣k−1−Pk∣k−1Hk⊤Kk⊤+Pk∣k−1Hk⊤Sk−1SkKk⊤=Pk∣k−1−KkHkPk∣k−1−Pk∣k−1Hk⊤Kk⊤+Pk∣k−1Hk⊤Kk⊤=Pk∣k−1−KkHkPk∣k−1(12)
推导到这里,基本上也就彻底糊涂一目了然了。接下来看看这些公式怎么用。
卡尔曼滤波器的操作包括两个阶段:预测与更新。在预测阶段,滤波器使用上一状态的估计,做出对当前状态的估计。在更新阶段,滤波器利用对当前状态的观测值优化在预测阶段获得的预测值,以获得一个更精确的新估计值。
在预测阶段,用式 (3) 和式 (8) 给出预测状态和预测估计协方差矩阵:
x^k∣k−1Pk∣k−1=Fkx^k−1∣k−1+Bkuk=FkPk−1∣k−1Fk⊤+Qk
在更新阶段,先用式 (4)、式 (7) 和式 (11) 分别计算测量余量、测量余量的协方差和最优卡尔曼增益:
y~kSkKk=zk−Hkx^k∣k−1=HkPk∣k−1Hk⊤+Rk=Pk∣k−1Hk⊤Sk−1
再用式 (5) 和式 (12) 分别计算更新后的状态估计和协方差估计:
x^k∣kPk∣k=x^k∣k−1+Kky~k=Pk∣k−1−KkHkPk∣k−1
只要知道初始时刻的 x^0∣0 和 P0∣0 就可以递归地计算 x^k∣k 和 Pk∣k 了(完