概率预测的目标是在满足 calibration 的前提下尽可能提高预测的 sharpness。所谓的 calibration 指的是预测分布和观测值在统计上的一致性,而 sharpness 则是指预测分布的集中程度。下面介绍一些常见的概率预测的评估方法。
对于观测值 ξ1,⋯,ξn ,假设模型预测的累积分布函数分别为 F1,⋯,Fn。如果模型预测准确,则概率积分变换 {Fi(ξi)}i=1n 应当服从标准的均匀分布 U(0,1)。
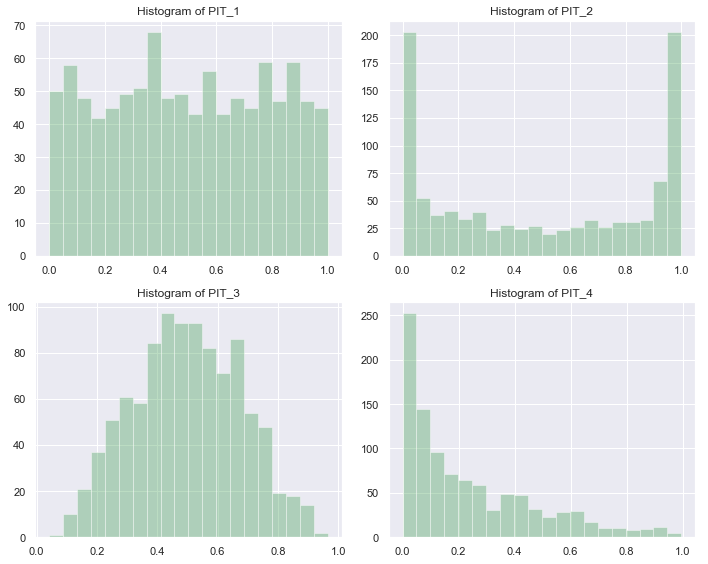
PIT 的优势之一是便于可视化。最简单的做法是画直方图。∪ 形的直方图意味着预测的分布过于集中;∩ 形的直方图意味着预测的分布过于分散;明显不对称的直方图则意味着预测的分布整体偏离真实值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import norm
sns.set()
obs = np.random.normal(loc=0, scale=1, size=1000)
pit_1 = norm.cdf(x=obs, loc=0, scale=1)
pit_2 = norm.cdf(x=obs, loc=0, scale=0.5)
pit_3 = norm.cdf(x=obs, loc=0, scale=2)
pit_4 = norm.cdf(x=obs, loc=1, scale=1)
plt.figure(figsize=(10, 8))
ax1 = plt.subplot(221)
sns.distplot(pit_1, bins=20, kde=False, color='g')
ax1.set_title('Histogram of PIT_1')
ax2 = plt.subplot(222)
sns.distplot(pit_2, bins=20, kde=False, color='g')
ax2.set_title('Histogram of PIT_2')
ax3 = plt.subplot(223)
sns.distplot(pit_3, bins=20, kde=False, color='g')
ax3.set_title('Histogram of PIT_3')
ax4 = plt.subplot(224)
sns.distplot(pit_4, bins=20, kde=False, color='g')
ax4.set_title('Histogram of PIT_4')
plt.tight_layout()
plt.show()
|
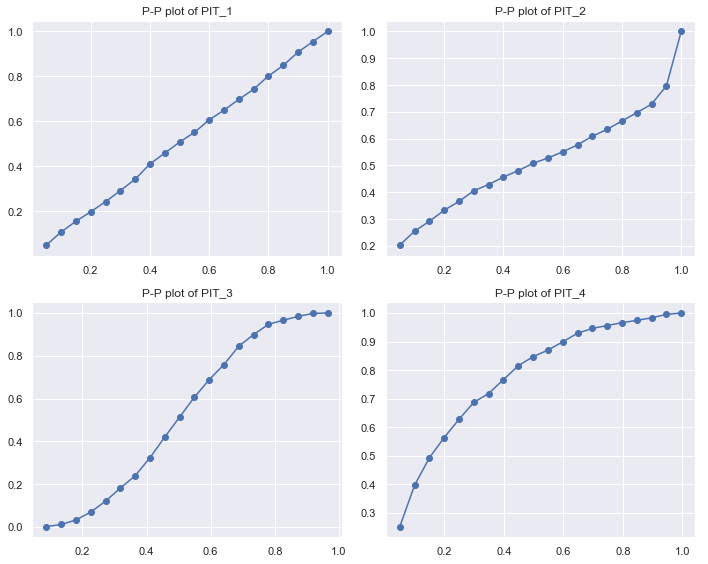
PIT 还可以用 P-P 图来展示。简单地说,就是画出 PIT 的 CDF 与标准均匀分布的 CDF 的关系图。如果预测准确,得到的应该是一条直线。反 sigmoid 曲线意味着预测的分布过于集中;sigmoid 曲线意味着预测的分布过于分散;其它曲线则意味着预测的分布可能已经整体偏离真实值了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| from scipy.stats import uniform
def get_pp(pit, bins):
hist, edges = np.histogram(pit, bins, range=(0,1))
cdf = np.cumsum(hist) / np.sum(hist)
cdf_u = uniform.cdf(x=edges[1:])
return cdf_u, cdf
plt.figure(figsize=(10, 8))
ax1 = plt.subplot(221)
plt.plot(*get_pp(pit_1, 20), '-o')
ax1.set_title('PP plot of PIT_1')
ax2= plt.subplot(222)
plt.plot(*get_pp(pit_2, 20), '-o')
ax2.set_title('PP plot of PIT_2')
ax3 = plt.subplot(223)
plt.plot(*get_pp(pit_3, 20), '-o')
ax3.set_title('PP plot of PIT_3')
ax4 = plt.subplot(224)
plt.plot(*get_pp(pit_4, 20), '-o')
ax4.set_title('PP plot of PIT_4')
plt.tight_layout()
plt.show()
|
2. 数值评分规则
2.1 连续概率排位分数(Continuous Ranked Probability Score,CRPS)
CRPS 是在概率预测领域使用最广泛的准确度指标之一。它的定义如下:
CRPS(Ff,Fo)=∫−∞+∞[Ff(x)−Fo(x)]2dx(1)
其中 Ff 是预测分布的 CDF,Fo 是观测值的 CDF。注意是平方的积分,千万不要误解为等于下图两条曲线之间的面积!!!
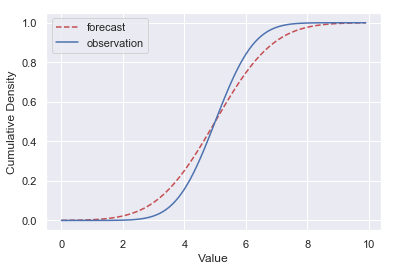
由定义可知,CRPS 衡量的是预测分布和真实分布的差异,当预测分布与真实分布完全一致时,CRPS 为零。预测分布过于集中、过于分散,亦或是偏离观测值太远都会导致 CRPS 增大。
多数情况下,真实分布是未知的。如果对一系列的观测值 ξ1,⋯,ξn 有各自对应的概率预测 F1,⋯,Fn,则可以用下式来估计 CRPS:
CRPS(F,ξ)=n1i=1∑ncrps(Fi,ξi)=n1i=1∑n∫−∞+∞[Fi(x)−ε(x−ξi)]2dx(2)
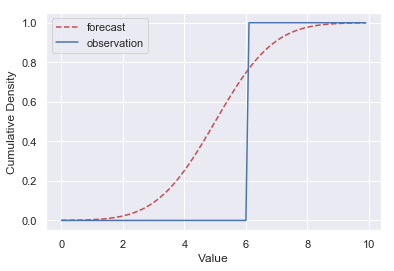
其中
ε(t)={0,t<01,t≥0(3)
为单位阶跃函数,如下图所示。
2.2 交叉熵(Cross Entropy)和对数分数(Logarithmic Score)
如前所述,CRPS 衡量的是预测分布与真实分布之间的差异。我们知道,机器学习分类问题中常用的损失函数交叉熵也是用来比较两个概率分布之间的差异的。
概率分布 p 和 q 的交叉熵定义为
H(p,q)=Ep[−log2q](4)
其中 p 为真实分布,q 为预测分布。
若 p 和 q 是离散的,则
H(p,q)=−x∑p(x)log2q(x)(5)
在真实分布未知的情况下,可以用下式来估计交叉熵:
H=−n1i=1∑nlog2q(ξi)(6)
其中 {ξi}i=1n 为观测值。
如果对一系列的观测值 ξ1,⋯,ξn 有各自对应的概率预测 F1,⋯,Fn,则对数分数(Logarithmic Score)定义为
LogS(F,ξ)=−n1i=1∑nlog2fi(ξi)(7)
其中 f 为 F 对应的 PDF。可以看到对数分数与交叉熵的估计式(6)形式上是相近的。
2.3 Brier Score
Brier Score 通常用于分类问题中,其定义为
BS=n1t=1∑ni=1∑r(fti−oti)2(8)
其中 n 是样本数量,r 是类目数量,fti 是模型预测第 t 个样本的类目为 i 的概率,oti 是第 t 个样本的真实状态(类目为 i 则取 1,否则取 0)。
3. 需要注意的问题
如前所述,真实分布已知的情况下,CRPS 可以直接计算。根据定义(1),预测准确(即预测分布与真实分布完全一致)时 CRPS 为零。但真实分布未知的情况下,CRPS 只能通过(2)估算。此时就算预测准确,CRPS 也不为零。且不同的真实分布,在同样预测准确的时候,对应的 CRPS 也不一样。下面给出一个简单的例子:
1
2
3
4
5
6
7
8
9
10
11
| >>> import numpy as np
>>> import properscoring as ps
>>> obs1 = np.random.normal(loc=0, scale=1, size=1000)
>>> crps1 = np.mean(ps.crps_gaussian(x=obs1, mu=0, sig=1))
>>> crps1
0.5795829266550281
>>> obs2 = np.random.normal(loc=0, scale=10, size=1000)
>>> crps2 = np.mean(ps.crps_gaussian(x=obs2, mu=0, sig=10))
>>> crps2
5.326040950564251
>>>
|
不能因为 crps1 比 crps2 小,就认为前者的预测更好,事实上它们都是对各自观测值真实分布的准确预测,因此是一样好的。在真实分布未知的情况下,CRPS 只适合用来衡量对同一个分布的不同预测之间的相对好坏,而不能衡量绝对的好坏。不难验证交叉熵也是如此。这与点估计中用到的各种准确率指标是不一样的。
怎样才能评估绝对的好坏呢?前面说过,预测准确的情况下,PIT 服从标准的均匀分布。如果计算 PIT 与标准均匀分布之间的 CRPS 或交叉熵,无论真实分布是怎样的,只要预测准确,结果都应该是接近的。
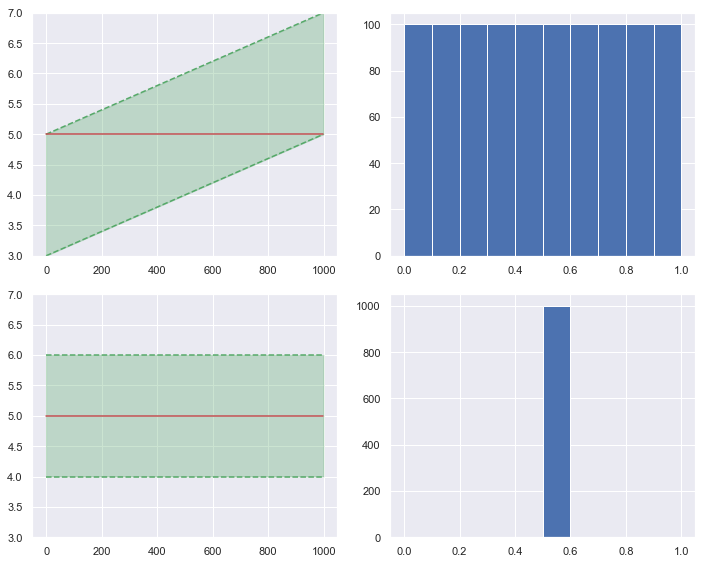
但 PIT 本身就没有问题了吗?如下图所示。左边两图中的红色实线表示真实值,绿色阴影表示预测的分布(采用均匀分布)。右边两图是对应的 PIT。从 PIT 得出的结论应该是上面的预测好,但上面这个真的是你需要的预测吗?
参考文献
[1] Gneiting, T., & Raftery, A. E. (2007). Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association, 102(477), 359–378.
[2] Friederichs, P., & Thorarinsdottir, T. L. (2012). Forecast verification for extreme value distributions with an application to probabilistic peak wind prediction. Environmetrics, 23(7), 579–594.
[3] Benedetti, R. (2010). Scoring Rules for Forecast Verification. Monthly Weather Review, 138(1), 203–211.
[4] Cross entropy - Wikipedia
[5] Barier score - Wikipedia