最近打算分享一些基于深度学习的时间序列预测方法。这是第三篇。
前面介绍的 DeepAR 和 DeepState 都是基于 RNN 的模型。RNN 是序列建模的经典方法,它通过递归来获得序列的全局信息,代价是无法并行。CNN 也可以用来建模序列,但由于卷积捕捉的是局部信息,CNN 模型往往需要通过叠加很多层才能获得较大的感受野。后续我可能会 (意思就是未必会) 介绍基于 CNN 的时间序列预测方法。Google 在 2017 年发表的大作 Attention Is All You Need 为序列建模提供了另一种思路,即单纯依靠注意力机制(Attention Mechanism),一步到位获得全局信息。Google 将这个模型称为 Transformer。Transformer 在自然语言处理、图像处理等领域都取得了很好的效果。Transformer 的结构如下图所示(误

今次要介绍的是一篇 NIPS 2019 的文章 Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting,该文章将 Transformer 模型应用到时间序列预测中,并提出了一些改进方向。
我们首先介绍注意力机制,然后简单介绍一下模型,最后给出一个 demo。
Attention
根据 Google 的方案,Attention 定义为
Attention(Q,K,V)=softmax(dkQK⊤)V
其中 Q∈Rn×dk, K∈Rm×dk, V∈Rm×dv。从矩阵的维度信息来看,可以认为 Attention 把一个 n×dk 的序列 Q 编码成一个 n×dv 的新序列。记 Q=[q1,q2,⋯,qn]⊤,K=[k1,k2,⋯,km]⊤,V=[v1,v2,⋯,vm]⊤,可以看到 k 和 v 是一一对应的。单看 Q 中的每一个向量,有
Attention(qt,K,V)=s=1∑mZ1exp(dkqtks⊤)vst=0,1,⋯,n
其中 Z 是 softmax 函数的归一化因子。从上式可以看出,每一个 qt 都被编码成了 v1,v2,⋯,vm 的加权和,vs 所占的权重取决于 qt 与 ks 的内积(点乘)。缩放因子 dk 起到一定的调节作用,避免内积很大时 softmax 的梯度很小。这种定义下的注意力机制被称为缩放点乘注意力(Scaled Dot-Product Attention)。
在 Attention 的基础上,Google 又提出了 Multi-Head Attention,其定义如下
MultiHead(Q,K,V)headiQiKiVi=Concat(head1,head2,⋯,headh)=Attention(Qi,Ki,Vi)=QWiQ=KWiK=VWiV
其中 WiQ,WiK∈Rdk×dk~,WiV∈Rdv×dv~。简单来说,就是把 Q、K 和 V 通过线性变换映射到不同的表示空间,然后计算 Attention;重复 h 次,把得到的 h 个 Attention 的结果拼接起来,最后输出一个 n×(hdv~) 的序列。
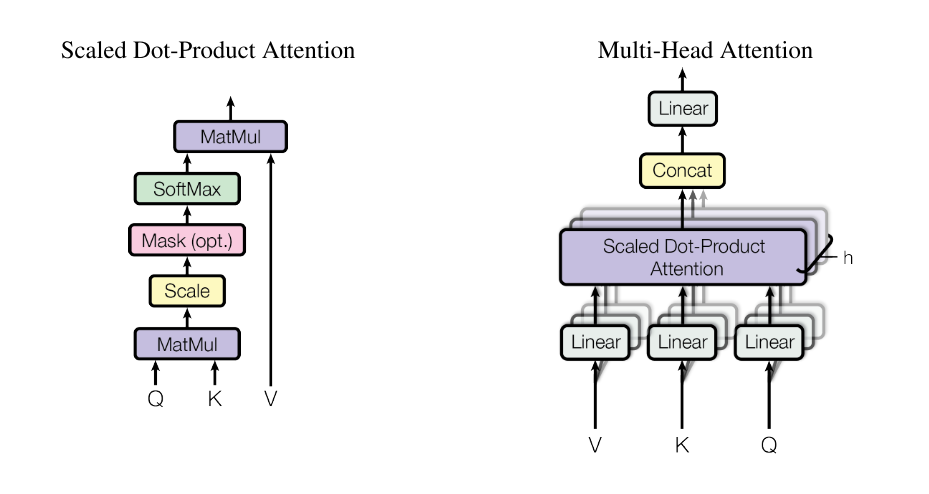
在 Transformer 中,大部分的 Attention 都是 Self Attention(“自注意力”或“内部注意力”),就是在一个序列内部做 Attention,亦即 Attention(X,X,X)。更准确地说,是 Multi-Head Self Attention,即 MultiHead(X,X,X)。Self Attention 可以理解为寻找序列 X 内部不同位置之间的联系。
Model
前面讲的基本上都是 Google 那篇 Transformer 文章的内容,现在我们回到时序预测这篇文章。为了避免混淆,我们用 Time Series Transformer 指代后者。
先回顾一下之前介绍的 DeepAR 模型:假设每个时间步的目标值 zt 服从概率分布 l(zt∣θt);先使用 LSTM 单元计算当前时间步的隐态 ht=LSTM(ht−1,zt−1,xt),再计算概率分布的参数 θt=θ(ht),最后通过最大化对数似然 ∑tlogl(zt∣θt) 来学习网络参数。Time Series Transformer 的网络结构与 DeepAR 类似,只是将 LSTM 层替换为 Multi-Head Self Attention 层,从而不需要递归,而是一次性计算所有时间步的 θt。如下图所示:
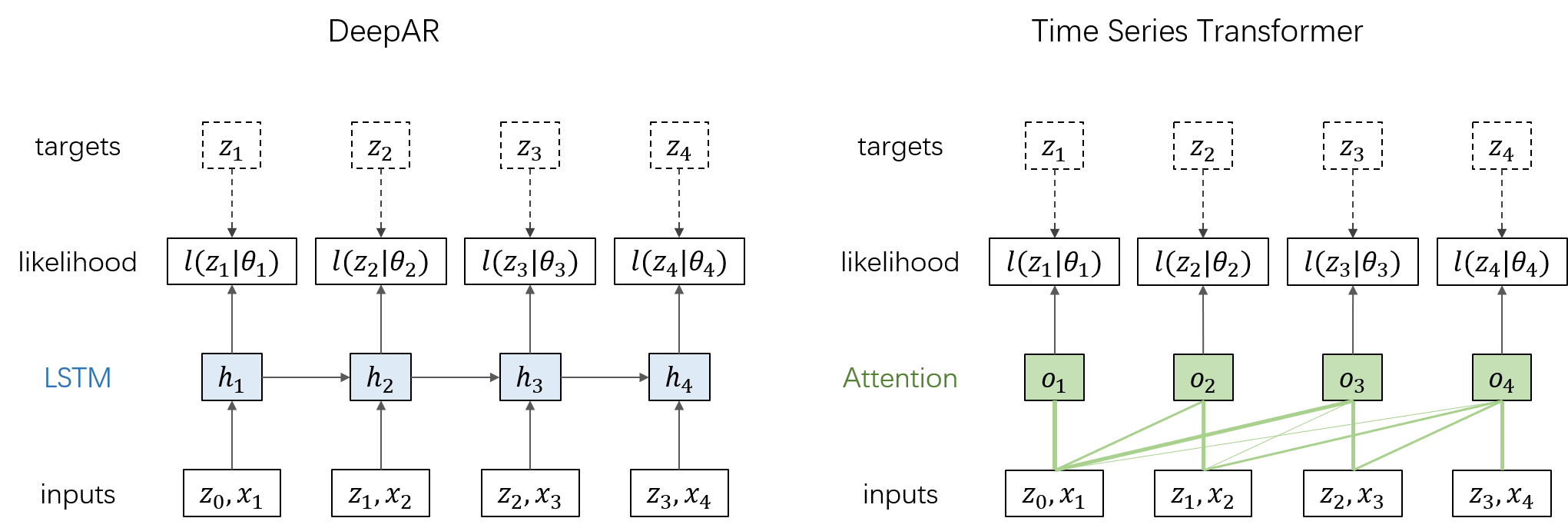
需要注意的是,对当前时间步做预测时,只能利用截止到当前时间步的输入。因此,在计算 Attention 时需要增加一个 Mask,将矩阵 QK⊤ 的上三角元素置为 −∞。
在此基础上,文章对模型又做了两个改进。
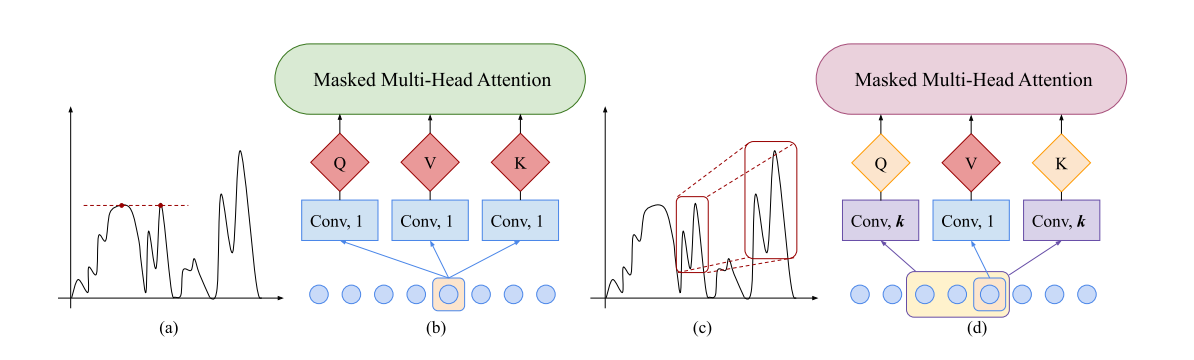
第一个改进点叫做 Enhancing the locality of Transformer,字面意思就是增强 Transformer 的局域性。时间序列中通常会有一些异常点,一个观测值是否应该被视作异常相当程度上取决于它所处的上下文环境。而 Multi-Head Self Attention
headi=softmax(dk~QiKi⊤⋅mask)ViQi=XWiQ,Ki=XWiK,Vi=XWiV
在计算序列内部不同位置的关系时,并没有考虑各个位置所处的局域环境,这会使预测容易受异常值的干扰。在博客的开头我们已经提到卷积操作可以用来捕捉局部信息。如果在计算 Qi 和 Ki 时使用卷积代替线性变换,就可以在 Self Attention 中引入局部信息。注意,由于当前时间步不能使用未来的信息,这里使用的是因果卷积(causal convolution)。后续介绍基于 CNN 的时序预测时,因果卷积还会扮演重要角色。
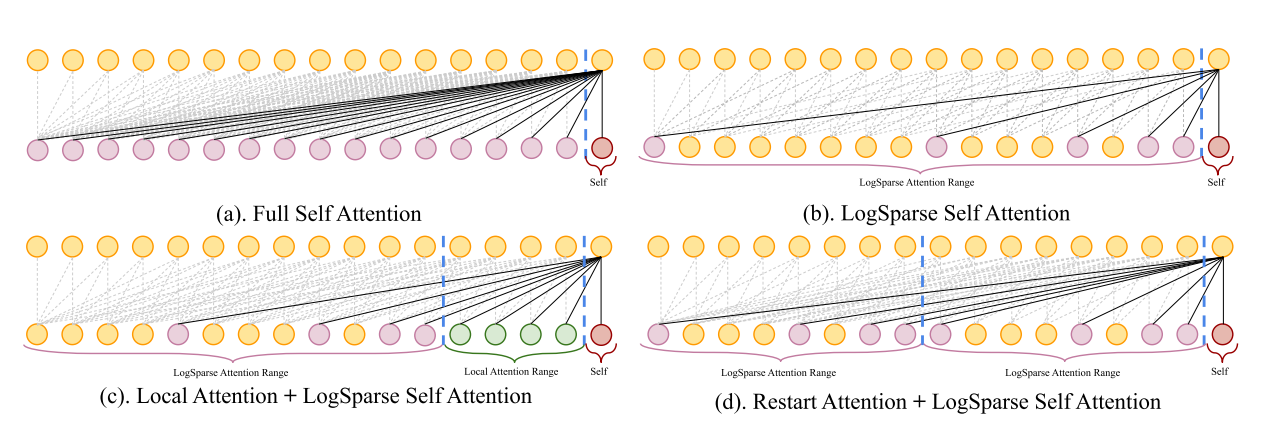
第二个改进点叫做 Breaking the memory bottleneck of Transformer. 假设序列长度为 n,Self Attention 的计算量为 O(n2)。在时序预测中,往往要考虑长程依赖,这种情况下 memory usage 就会比较可观了。针对这一问题,文章提出了 LogSparse Self Attention 结构,使计算量减少到 O(n(logn)2),如下图所示。
Code
按照惯例,这里给出一个基于 TensorFlow 的简单 demo。需要说明的是,本 demo 没有实现 LogSparse Self Attention。
以下定义了 Attention 层和 Transformer 模型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
| import tensorflow as tf
class Attention(tf.keras.layers.Layer):
"""
Multi-Head Convolutional Self Attention Layer
"""
def __init__(self, dk, dv, num_heads, filter_size):
super().__init__()
self.dk = dk
self.dv = dv
self.num_heads = num_heads
self.conv_q = tf.keras.layers.Conv1D(dk * num_heads, filter_size, padding='causal')
self.conv_k = tf.keras.layers.Conv1D(dk * num_heads, filter_size, padding='causal')
self.dense_v = tf.keras.layers.Dense(dv * num_heads)
self.dense1 = tf.keras.layers.Dense(dv, activation='relu')
self.dense2 = tf.keras.layers.Dense(dv)
def split_heads(self, x, batch_size, dim):
x = tf.reshape(x, (batch_size, -1, self.num_heads, dim))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, inputs):
batch_size, time_steps, _ = tf.shape(inputs)
q = self.conv_q(inputs)
k = self.conv_k(inputs)
v = self.dense_v(inputs)
q = self.split_heads(q, batch_size, self.dk)
k = self.split_heads(k, batch_size, self.dk)
v = self.split_heads(v, batch_size, self.dv)
mask = 1 - tf.linalg.band_part(tf.ones((batch_size, self.num_heads, time_steps, time_steps)), -1, 0)
dk = tf.cast(self.dk, tf.float32)
score = tf.nn.softmax(tf.matmul(q, k, transpose_b=True)/tf.math.sqrt(dk) + mask * -1e9)
outputs = tf.matmul(score, v)
outputs = tf.transpose(outputs, perm=[0, 2, 1, 3])
outputs = tf.reshape(outputs, (batch_size, time_steps, -1))
outputs = self.dense1(outputs)
outputs = self.dense2(outputs)
return outputs
class Transformer(tf.keras.models.Model):
"""
Time Series Transformer Model
"""
def __init__(self, dk, dv, num_heads, filter_size):
super().__init__()
self.attention = Attention(dk, dv, num_heads, filter_size)
self.dense_mu = tf.keras.layers.Dense(1)
self.dense_sigma = tf.keras.layers.Dense(1, activation='softplus')
def call(self, inputs):
outputs = self.attention(inputs)
mu = self.dense_mu(outputs)
sigma = self.dense_sigma(outputs)
return [mu, sigma]
|
关于损失函数和训练部分,请参考我们在介绍 DeepAR 时给出的 demo。
为了验证代码,我们随机生成一个带有周期的时间序列。下图展示了这个序列的一部分数据点。
与 DeepAR 有所不同的是,由于 Attention 结构并不能很好地捕捉序列的顺序,我们加入了相对位置作为特征。
经过训练后用于预测,效果如下图所示,其中阴影部分表示 0.05 分位数 ~ 0.95 分位数的区间。
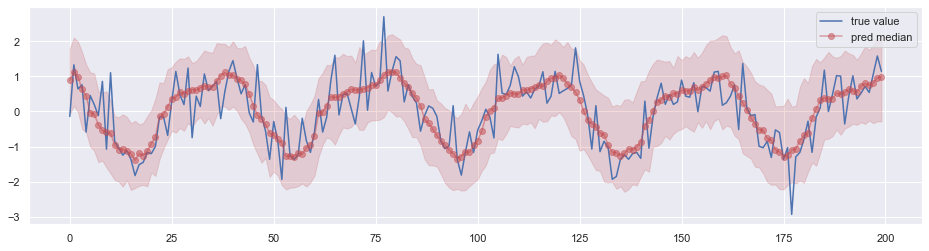
与 DeepAR 对比
- 从某种意义上来说,两者的网络结构很像,学习的也都是概率分布的参数。
- Attention 结构本身不能很好地捕捉序列的顺序,当然这个不是大问题,因为通常来说时序预测任务都会有时间特征,不需要像自然语言处理时那样加入额外的位置编码。
- 该文章中给出的实验结果表明 Time Series Transformer 在捕捉长程依赖方面比 DeepAR 更有优势。
- Time Series Transformer 在训练的时候可以并行计算,这是优于 DeepAR 的。不过因为和 DeepAR 一样采用了自回归结构,预测的时候无法并行。不仅如此,DeepAR 预测单个时间步时只需要使用当前输入和上一步输出的隐态即可;而 Transformer 却需要计算全局的 Attention。因此在预测的时候,Transformer 的计算效率很可能不如 DeepAR。